Unsupervised Learning 입니다
k개의 그룹을 만든다.
즉, 비슷한 특징을 갖는 것들끼리 묶는 것
다음을 2개, 3개, 4개 그룹 등등 원하는 그룹으로 만들 수 있다.

알고리즘



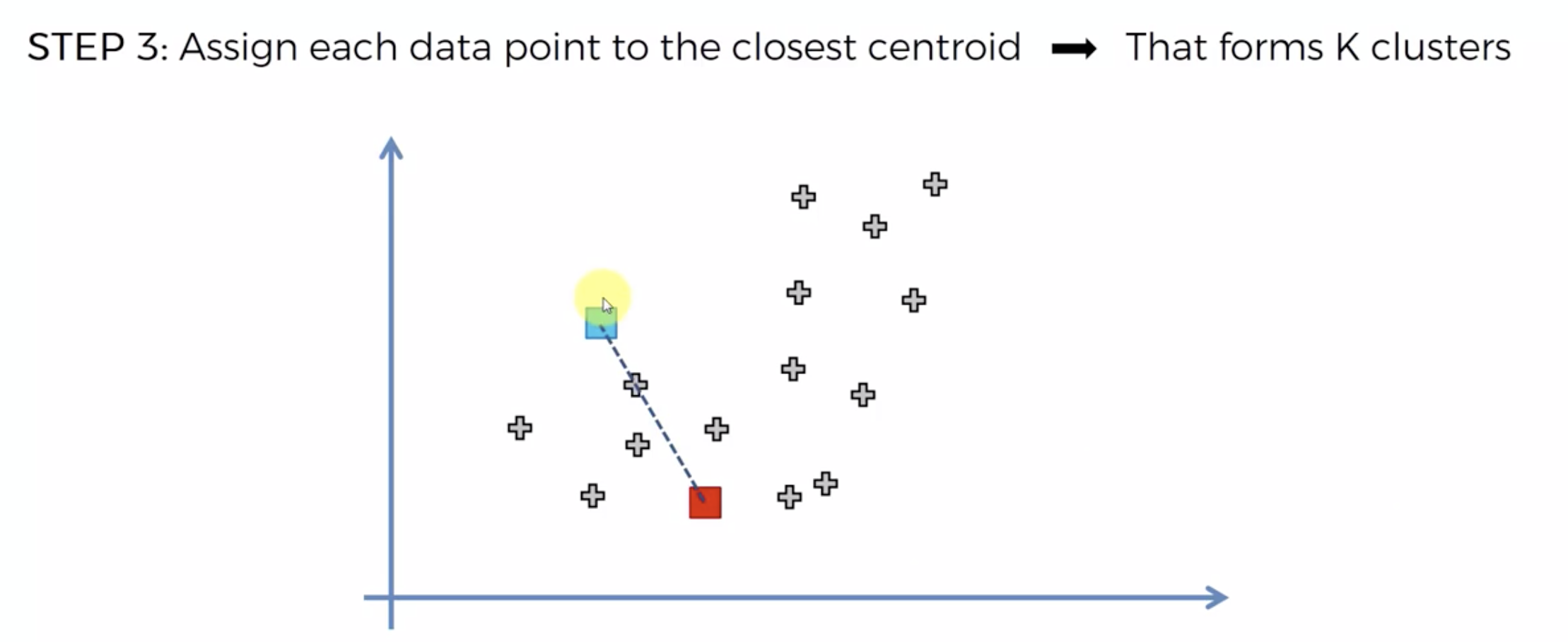




또 다시 중심에 직교하는 선을 긋고, 자신의 영역안에 있는 것들을 자신의 색으로 바꾼다.
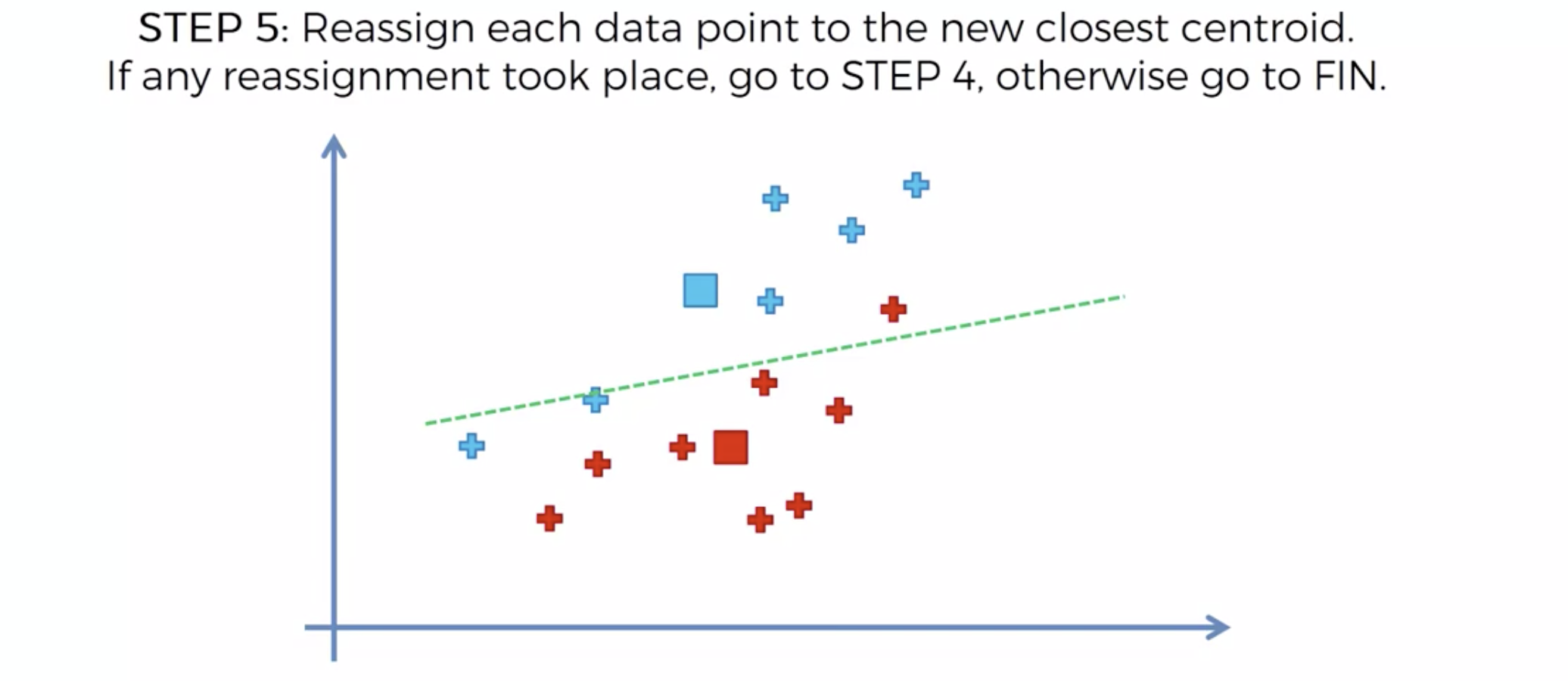




중심을 이동해서, 영역을 나눴는데, 나눈 영역안에 다른 카테고리가 더 이상 나타나지 않으면, 끝냅니다.

Random Initialization Trap
다음과 같은 데이터 분포가 있다고 가정했을 때
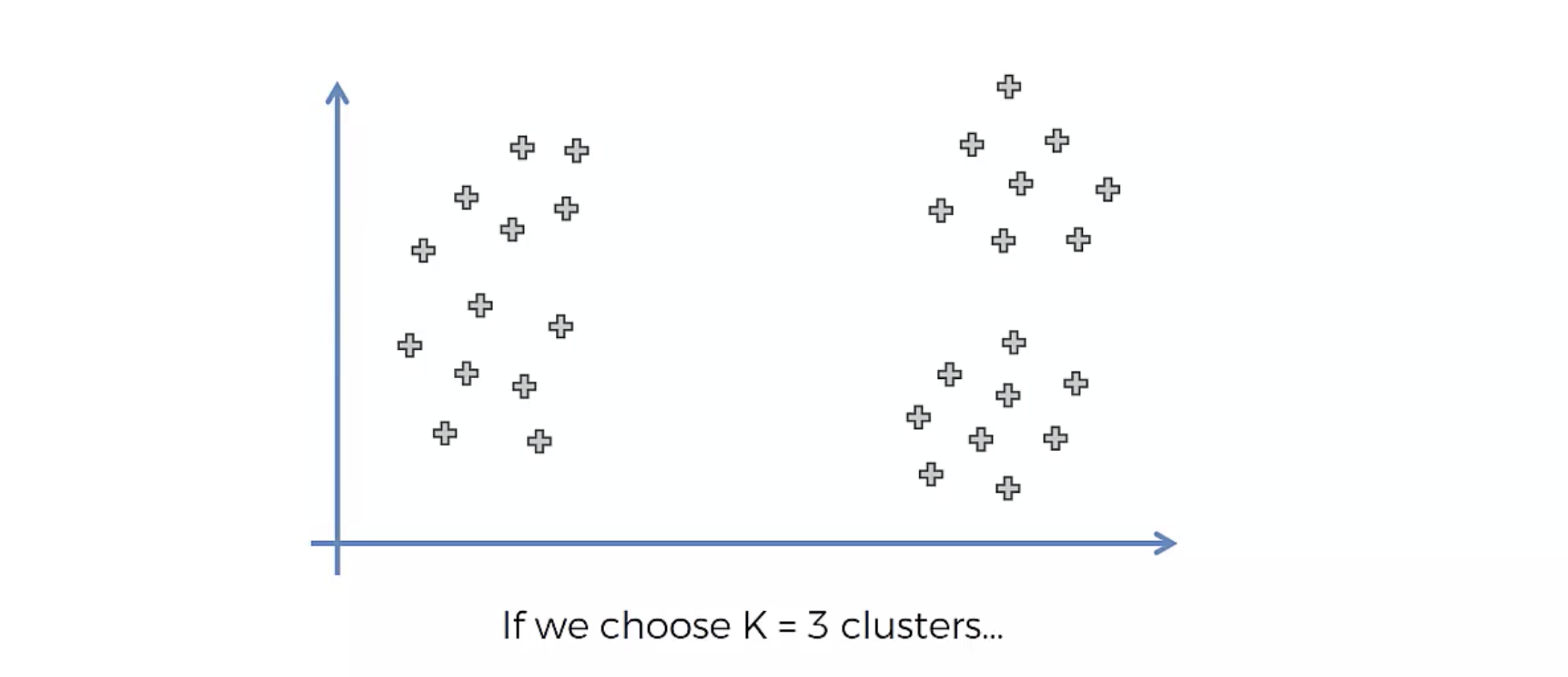
우리가 원하는 클러스터링 그룹화는, 아래와 같은 것입니다.





원치 않는 그룹화가 되어버렸습니다.

위와 같은 문제를 해결한 것이, K-Means++ 알고리즘입니다.

몇개로 분류할지는 어떻게 결정할까?
K의 개수를 정하는 방법
within-cluster sums of sqsuares
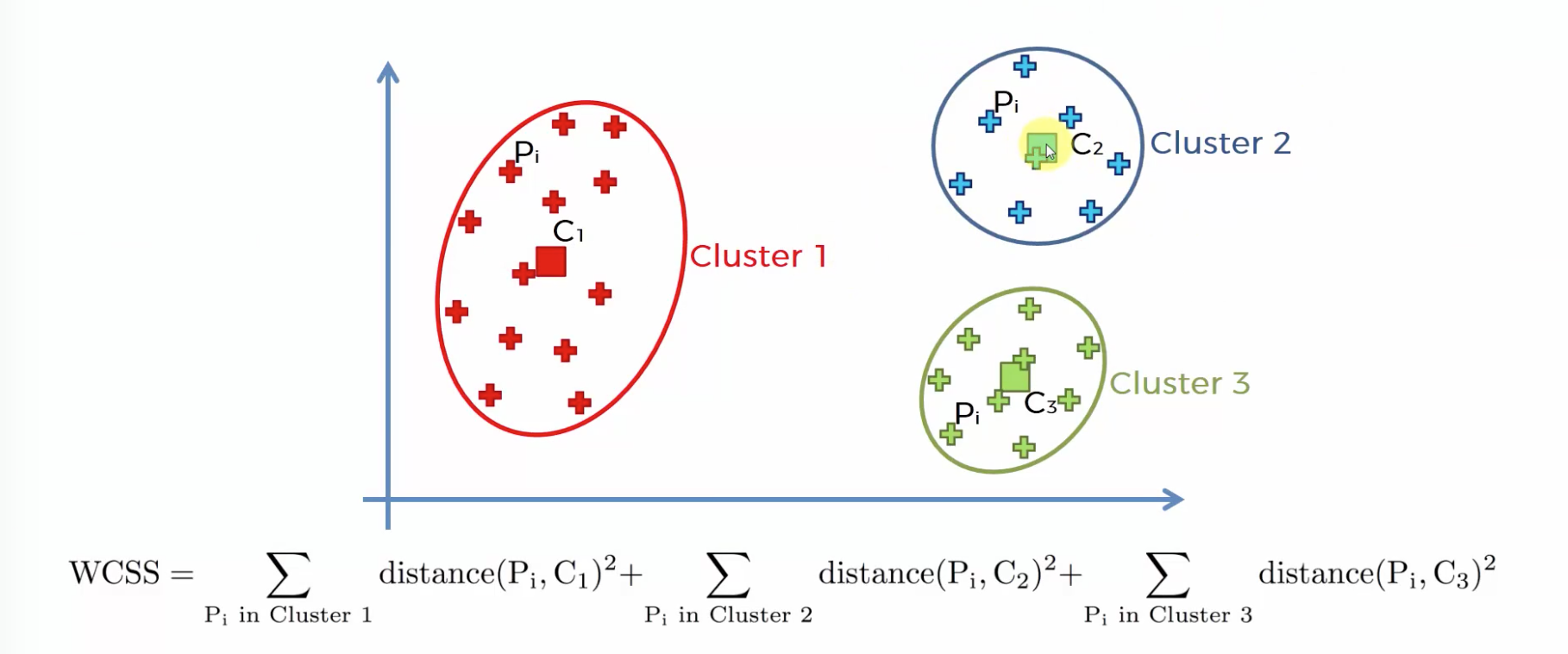
센터가 원소들과의 거리가 멀수록 값이 커진다.
따라서 최소값에 가까워지는 개수를 뽑되, 개수가 너무 많아지면 차별성이 없어집니다.


'머신러닝' 카테고리의 다른 글
| Hierarchical Clustering 과 Dendrogram 보기 (0) | 2022.03.28 |
|---|---|
| K-Means Clustering 예시풀이 (0) | 2022.03.28 |
| Decision Tree (0) | 2022.03.28 |
| Support Vector Machine (0) | 2022.03.28 |
| K-Nearest Neighbor (K-NN) (0) | 2022.03.28 |