다음처럼 카테고리가 레이블링 되어 있는 데이터가 존재합니다.
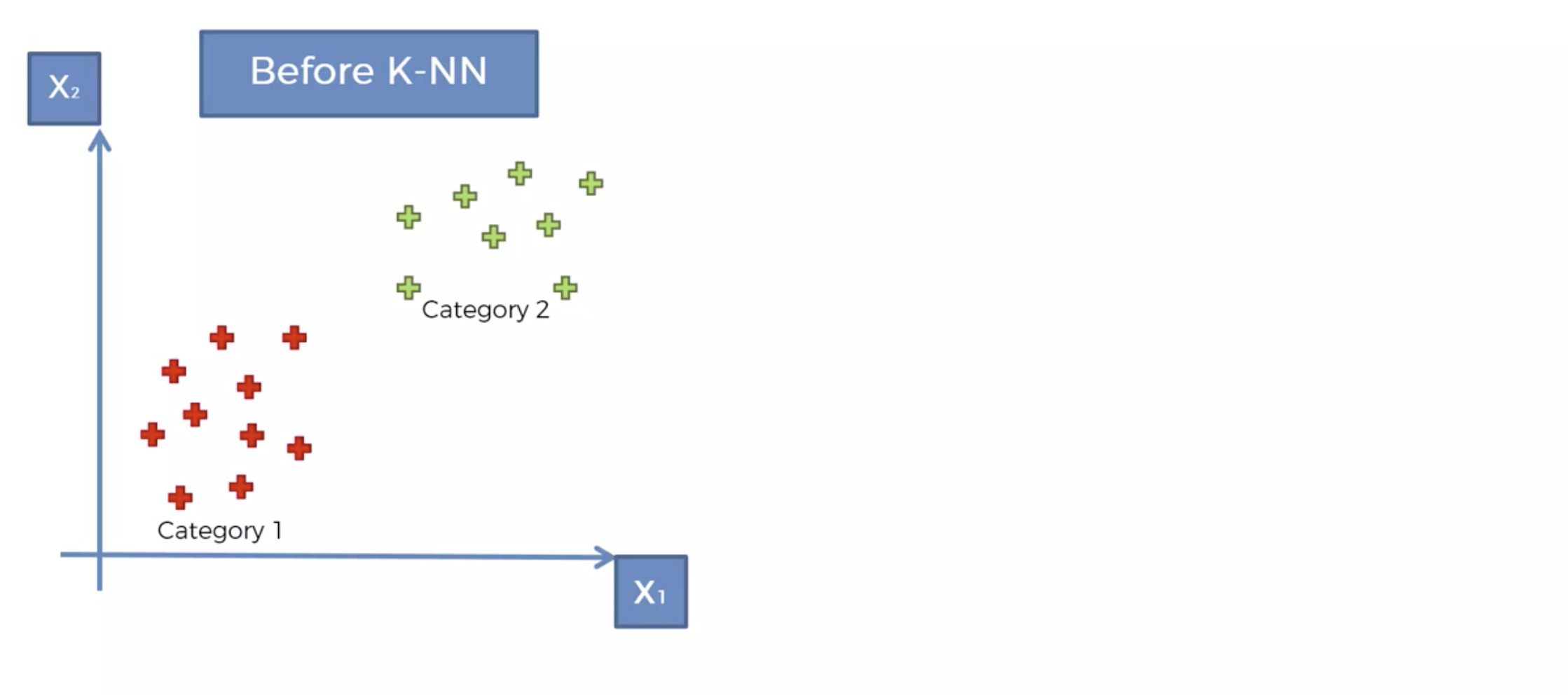
새로운 데이터가 생겼을때, 이를 어디로 분류해야 할까..

왜 빨간색으로 분류를 했을까요
hyper parameter : 우리가 결정해줘야 하는 파라미터(항목)
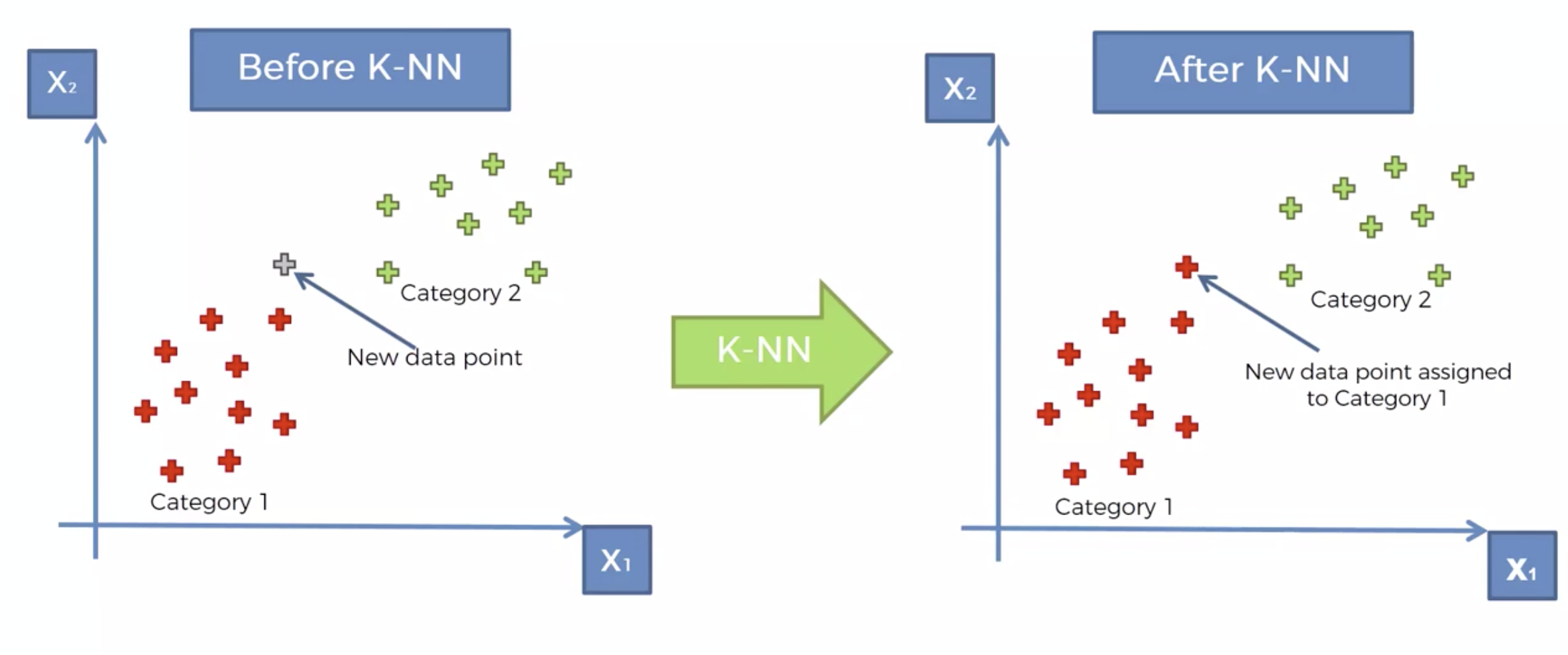
K-NN 알고리즘
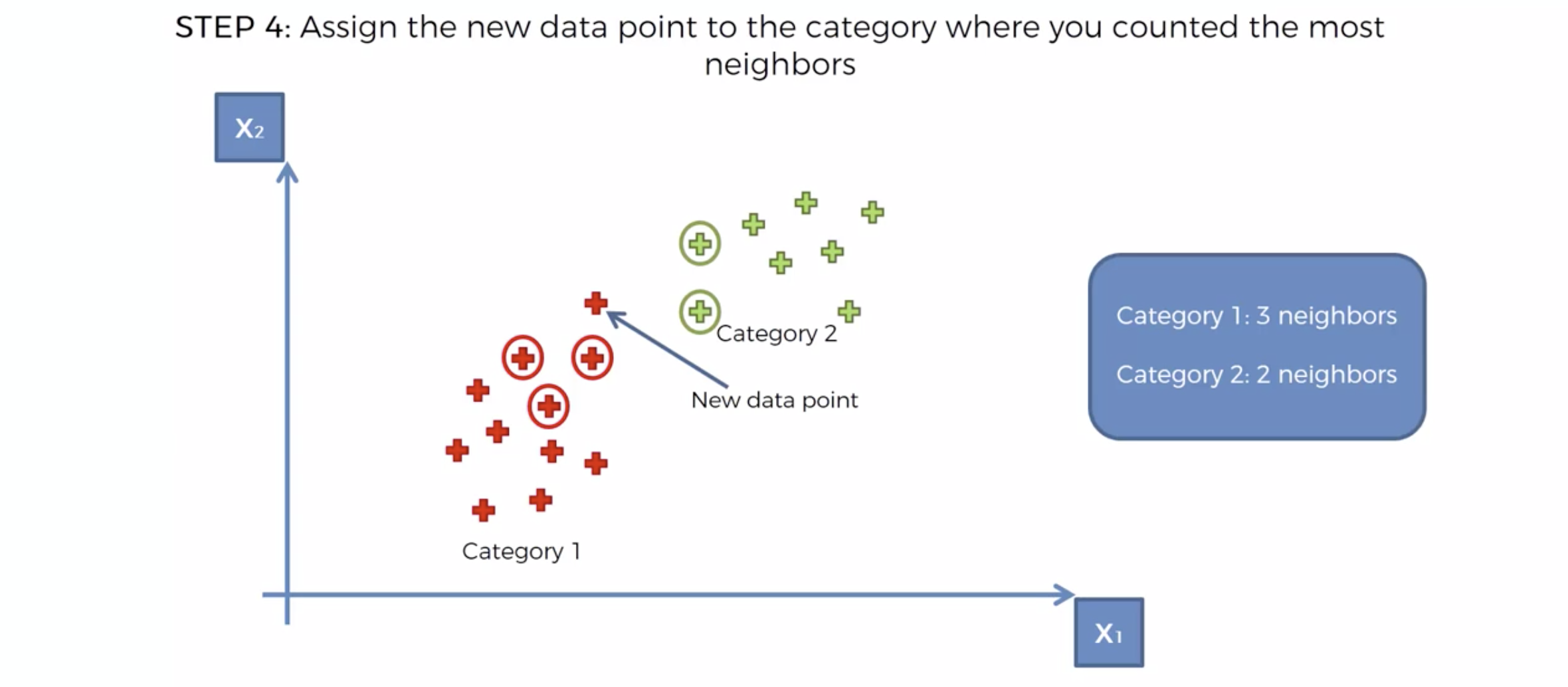
내 주위에 몇개의 이웃을 확인해 볼 것 인가를 결정한다. => K

새로운 데이터가 발생 시, Euclidean distance에 의해서, 가장 가까운 K개의 이웃을 택한다.

K개의 이웃의 카테고리를 확인한다.

카테고리의 숫자가 많은 쪽으로, 새로운 데이터의 카테고리를 정해버린다.
구글드라이브 import
from google.colab import drive
drive.mount('/content/drive')필요한 라이브러리 한글 가능 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb
%matplotlib inline
import platform
from matplotlib import font_manager, rc
plt.rcParams['axes.unicode_minus'] = False
if platform.system() == 'Darwin':
rc('font', family='AppleGothic')
elif platform.system() == 'Windows':
path = "c:/Windows/Fonts/malgun.ttf"
font_name = font_manager.FontProperties(fname=path).get_name()
rc('font', family=font_name)
else:
print('Unknown system... sorry~~~~')
df=pd.read_csv('/content/drive/MyDrive/위치/Social_Network_Ads.csv')
X=df.iloc[:,[2,3]]
y = df['Purchased']
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X=scaler.fit_transform(X)
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.25,random_state=3)X와 y를 정해주고 스캐일링 해줍니다
K-NN으로 모델링 합니다.
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5)
classifier.fit(X_train,y_train)
#검증
y_pred=classifier.predict(X_test)y_test는 인공지능이 볼 시험
y_testy_pred는 테스트 후
y_predfrom sklearn.metrics import confusion_matrix,accuracy_score
cm=confusion_matrix(y_test,y_pred)
cmaccuracy_score(y_test,y_pred)저는 91프로 나왔습니다.
sb.heatmap(data=cm,annot=True,cmap='RdPu',linewidths=0.5)
plt.show()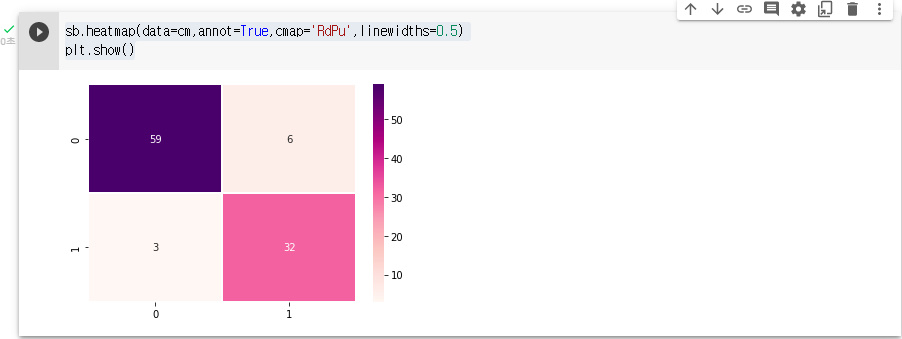

from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1,
stop = X_set[:, 0].max() + 1, step = 0.01),
np.arange(start = X_set[:, 1].min() - 1,
stop = X_set[:, 1].max() + 1, step = 0.01))
plt.figure(figsize=[10,7])
plt.contourf(X1, X2, classifier.predict(
np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1],
c = ListedColormap(('red', 'green'))(i), label = j)
plt.title('Classifier (Test set)')
plt.legend()
plt.show()
직선 : Linear
직선이 아는것들 : non - Linear
'머신러닝' 카테고리의 다른 글
| Decision Tree (0) | 2022.03.28 |
|---|---|
| Support Vector Machine (0) | 2022.03.28 |
| Logistic Regression , Confusion Matrix (0) | 2022.03.28 |
| Multiple Linear Regression (0) | 2022.03.28 |
| Linear Regression (0) | 2022.03.28 |