먼저 아나콘다에 scikit learn이 설치되어야 합니다
설치가 안되었으면 다음으로 설치합니다.
$ conda install -c conda-forge scikit-learn
Colab환경에서 진행함으로 구글 드라이브를 import 합니다.
from google.colab import drive
drive.mount('/content/drive')
데이터처리에 필요한 파이브러리들을 import 합니다.
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
데이터처리할 csv파일을 구글 드라이브에 옮긴 뒤 Colab으로 불러온 후 변수 처리합니다.
df=pd.read_csv('/content/drive/MyDrive/위치/Data.csv')

Nan값 처리합니다.

지금 데이터는 육안으로도 Nan값을 파악하기 쉽지만, 데이터가 많아지면 많아질수록 힘들어지기 때문에 isna를 통해 찾아냅니다.
Age컬럼에 한개 Salary컬럼에 한개
Nan값을 처리하는 방법은 두가지입니다.
첫번째로 Nan값을 삭제하거나,

Nan값이 하나라도 들어있는 데이터는 모두 삭제됩니다.
두번째로 Nan값을 평균값으로 채우는 방법입니다.

평균으로 채운 뒤 변수에 다시 저장합니다.
이제 X,y 데이터를 분리합니다.
이유는 Testing할 변수와 labeling할 변수입니다. (학습변수와 정답(?)변수)
X를 종속변수
y를 독립변수
X = df.loc[ : ,'Country':'Salary']
y = df['Purchased']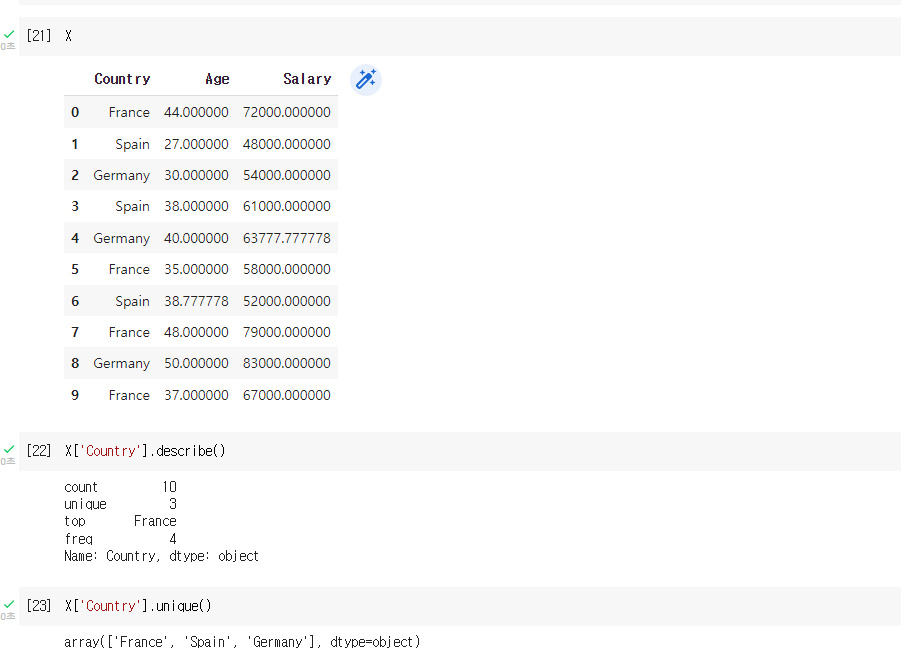

X에 학습변수를 담았지만 문자로 되어있는 데이터는 방정식에 대입할 수가 없습니다.
따라서 문자를 숫자로 바꿔줘야 합니다.
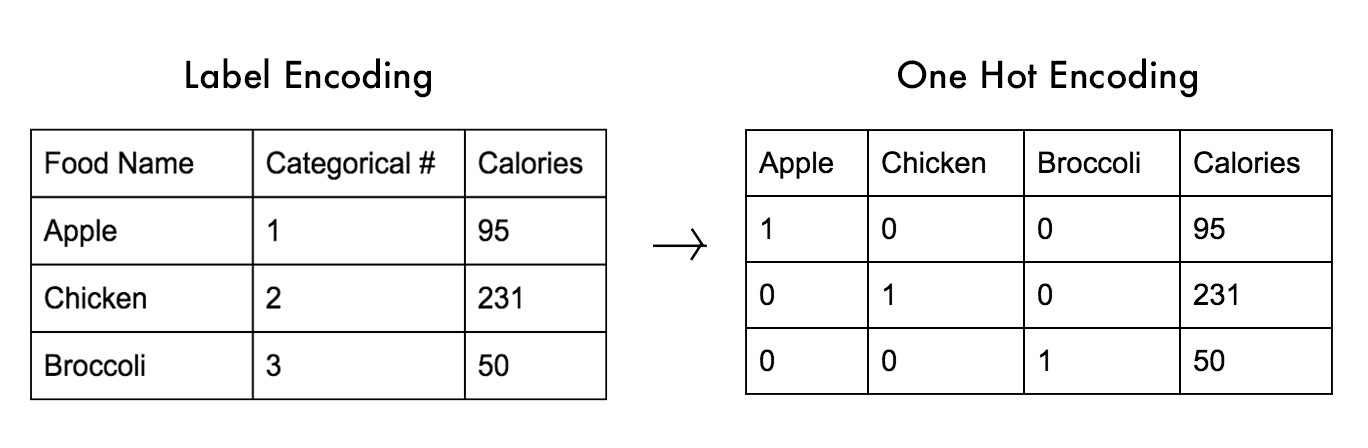
먼저 해당 문자열이 카테고리컬 데이터인지 확인합니다.
카테고리컬 데이터이면 정렬합니다.
정렬한 후의 문자열들을 앞에서 0부터 시작한 숫자로 변환합니다.
이것이 가장 기본적인 방법인데, 이를 Label Encoding이라고 합니다.
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer1. 레이블 인코딩하는 방법

2. 원 핫 인코딩하는 방법

ct = ColumnTransformer( [('encoder',OneHotEncoder(),[0])] ,
remainder='passthrough') # remainder='passthrough' = 나머지 컬럼은 그대로 사용
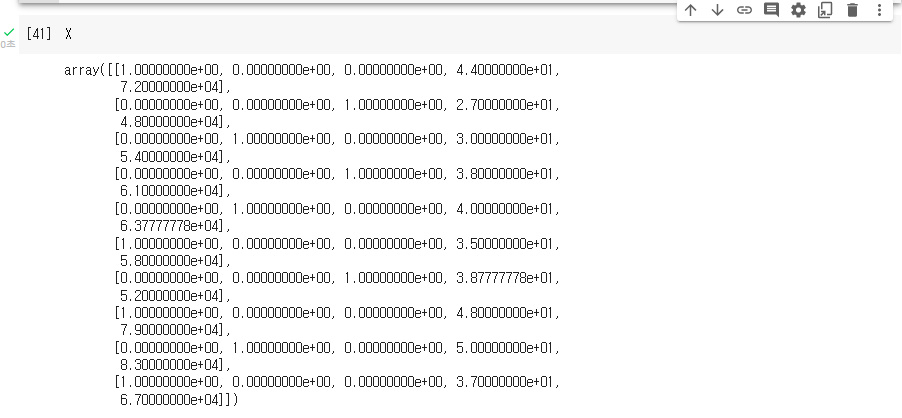
X=ct.fit_transform(X) # 원핫 인코딩이 수행된 컬럼은 항상 행렬의 맨 왼쪽에 나온다.0 이라고 쓴 이유는 X에서 원핫인코딩할 컬럼이, 컴퓨터가 매기는 인덱스로 0이기 때문에 0입니다.
만약에 Salary 컬럼도 원핫인코딩 한다고 가정한다면 [0,2] 라고 컴퓨터가 매기는 인덱스를 추가로 적어주면 됩니다.

Dataset을 Training용과 Test용으로 나눈다.
숫자로 다 변환된 X와 y를 학습용 데이터와 테스트용 데이터로 나눈다.
그 결과는 총 4개의 데이터가 나옵니다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=3)
Feature Scaling
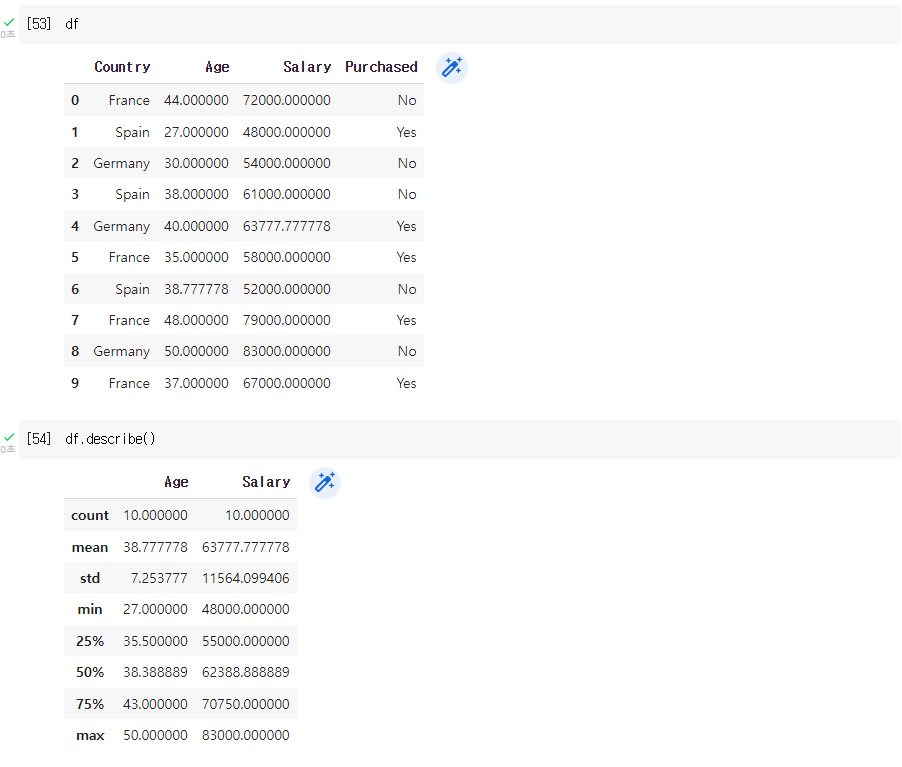
Age 와 Salary 는 같은 스케일이 아니다.
Age 는 27 ~ 50 Salary 는 40k ~ 90k
유클리디언 디스턴스로 오차를 줄여 나가는데, 하나의 변수는 오차가 크고, 하나의 변수는 오차가 작으면, 나중에 오차를 수정할때 편중되게 된다.
따라서 값의 레인지를 맞춰줘야 정확히 트레이닝 된다.

Feature Scaling 2가지 방법
표준화 : 평균을 기준으로 얼마나 떨어져 있느냐? 같은 기준으로 만드는 방법, 음수도 존재, 데이터의 최대최소값 모를때 사용.
정규화 : 0 ~ 1 사이로 맞추는 것 데이터의 위치 비교가 가능, 데이터의 최대최소값 알때 사용

from sklearn.preprocessing import StandardScaler,MinMaxScaler
# X에는 피쳐 스케일링이 필요하다.
# 따라서 X용 스탠다드 스케일러 만들어서 사용한다.
s_scaler = StandardScaler()
X_train_s=s_scaler.fit_transform(X_train)
X_test_s=s_scaler.transform(X_test)y는 피쳐스케일링이 필요할까요?
이미 0과 1로 되어있으므로 피쳐스케일링이 필요없습니다.
#노멀리제이션으로 피처스케일링 한 경우
m_scaler = MinMaxScaler()
X_train_m=m_scaler.fit_transform(X_train)
X_test_m = m_scaler.transform(X_test)
# 오차 = 실제값 - 예측값 오차에러
'머신러닝' 카테고리의 다른 글
| K-Nearest Neighbor (K-NN) (0) | 2022.03.28 |
|---|---|
| Logistic Regression , Confusion Matrix (0) | 2022.03.28 |
| Multiple Linear Regression (0) | 2022.03.28 |
| Linear Regression (0) | 2022.03.28 |
| Machine Learning (머신 러닝)의 Supervised Learning의 정의와 용어 (0) | 2021.11.30 |