이미지 파일 다운로드
말, 사람을 분류하기 위한 사진 파일 다운로드하기
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/horse-or-human.zip \
-O /tmp/horse-or-human.zip확인용
! wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/validation-horse-or-human.zip \
-O /tmp/validation-horse-or-human.zip
압축풀기
import os
import zipfile
filename = '/tmp/horse-or-human.zip'
zip_ref = zipfile.ZipFile(filename,mode='r')
zip_ref.extractall('/tmp/horse-or-human')
zip_ref.close()
import zipfile
filename = '/tmp/validation-horse-or-human.zip'
zip_ref = zipfile.ZipFile(filename,mode='r')
zip_ref.extractall('/tmp/validation-horse-or-human')
zip_ref.close()
사진이 저장된 폴더 경로 만들기
train_horse_dir = '/tmp/horse-or-human/horses'
train_human_dir = '/tmp/horse-or-human/humans'
validation_horse_dir = '/tmp/validation-horse-or-human/horses'
validation_human_dir = '/tmp/validation-horse-or-human/humans'
각 폴더에 저장되어 있는 사진파일 이름들 출력하기
train_horse_names = os.listdir(train_horse_dir)
train_human_names = os.listdir(train_human_dir)
validation_horse_names = os.listdir(validation_horse_dir)
validation_human_names = os.listdir(validation_human_dir)
#잘 나오는 지 확인용
print(validation_horse_names)
print(validation_human_names)
각 디렉토리에 저장된 파일의 개수 확인

시각화로 사진 이미지 확인해 보기
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# Parameters for our graph; we'll output images in a 4x4 configuration
nrows = 4
ncols = 4
# Index for iterating over images
pic_index = 0말 8마리, 사람 8명씩 이미지 확인하기
# Set up matplotlib fig, and size it to fit 4x4 pics
fig = plt.gcf()
fig.set_size_inches(ncols * 4, nrows * 4)
pic_index += 8
next_horse_pix = [os.path.join(train_horse_dir, fname)
for fname in train_horse_names[pic_index-8:pic_index]]
next_human_pix = [os.path.join(train_human_dir, fname)
for fname in train_human_names[pic_index-8:pic_index]]
for i, img_path in enumerate(next_horse_pix+next_human_pix):
# Set up subplot; subplot indices start at 1
sp = plt.subplot(nrows, ncols, i + 1)
sp.axis('Off') # Don't show axes (or gridlines)
img = mpimg.imread(img_path)
plt.imshow(img)
plt.show()
간단한 모델링 하기
사진의 결과는 2개중의 하나이기 때문에 맨 마지막 액티베이션 함수는 시그모이드를 사용합니다.
필요한 라이브러리 import
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D,MaxPooling2D,Flatten,Dense
모델링 함수
def build_model():
model = Sequential()
model.add(Conv2D(filters=16,kernel_size=(3,3),activation='relu',input_shape=(300,300,3)))
model.add(MaxPooling2D(pool_size=(2,2),strides=2))
model.add(Conv2D(filters=32,kernel_size=(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2),strides=2))
model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2),strides=2))
model.add(Flatten())
model.add(Dense(units=512,activation='relu'))
model.add(Dense(units=1,activation='sigmoid'))
return model
모델 생성, 요약
model = build_model()
model.summary()RMSprop optimization algorithm 사용하여 컴파일
from tensorflow.keras.optimizers import RMSprop,Adam,Adagrad,Adadelta #RMSprop 보폭
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(learning_rate=0.001),
metrics=['accuracy'])파일로 되어있는 이미지를 학습을 위해서 넘파이로 바꿔줘야 합니다.
실제로 복잡한 작업을 해야 하는것을 텐서플로우에서 쉽게 처리할수있게 라이브러리를 제공합니다.
ImageDataGenerator
from tensorflow.keras.preprocessing.image import ImageDataGenerator파일로 되어있는 이미지의 피쳐스케일링을 합니다 -> 255.0으로 나누는 것
train_datagen = ImageDataGenerator(rescale=1/255.0)
validation_datagen = ImageDataGenerator(rescale=1/255.0)파일이 들어있는 디렉토리를 알려주고, 이미지 사이즈 정보도 알려주고, 분류할 정보도 알려줍니다.
target_size 파라미터는 우리가 마음대로 정해줄수있습니다.
단 모델의 input_shape과 동일해야합니다.
class_mode는, 2개 분류는 binary, 3개이상은 categorical로 설정
train_generator = train_datagen.flow_from_directory('/tmp/horse-or-human',target_size=(300,300),class_mode='binary')train_generator는 X_train과 y_train이 들어있게 됩니다.
y_train의 값은 폴더의 이름으로 설정됩니다.
따라서 폴더의 이름을 알파벳순으로 정렬한수 0부터 차례로 숫자를 매깁니다.
validation_generator = validation_datagen.flow_from_directory('/tmp/validation-horse-or-human',target_size=(300,300),class_mode='binary')
모델 학습
전체 데이터수는 = batch_size x steps_per_epoch 와 같습니다.
1000 = 20 x 50
epoch_history = model.fit(train_generator,epochs=30,steps_per_epoch=8,validation_data=validation_generator)
모델 결과, 시각화
model.evaluate(validation_generator)
plt.plot(epoch_history.history['accuracy'])
plt.plot(epoch_history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(['Train','Validation'])
plt.savefig('chart1.jpg')
plt.show()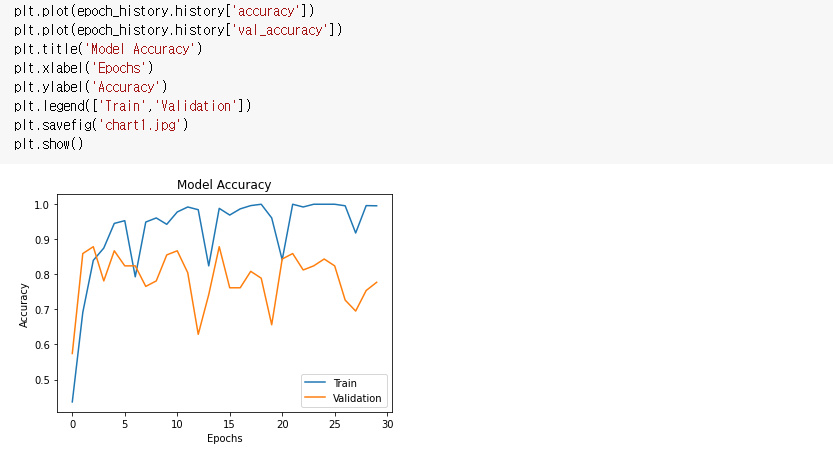
import numpy as np
from google.colab import files
from tensorflow.keras.preprocessing import image
uploaded = files.upload()
for fn in uploaded.keys() :
path = '/content/' + fn
img = image.load_img(path, target_size=(300,300)) #target_size를 맞게 변경
x = image.img_to_array(img)
print(x.shape)
x = np.expand_dims(x, axis = 0)
print(x.shape)
images = np.vstack( [x] )
classes = model.predict( images, batch_size = 10 )
print(classes)
if classes[0] > 0.5 : #분류할 데이터의 이름을 맞게 변경하세요.
print(fn + " is a human")
else :
print(fn + " is a horse")이 코드를 실행하고 파일 선택에 사람 또는 말 사진을 넣으면 지금까지 만든 모델이 분류를 해줍니다.
'딥러닝' 카테고리의 다른 글
| CNN 이용하여 정교한 이미지 분류 (강아지, 고양이 분류) (0) | 2022.03.29 |
|---|---|
| Convolutional Neural Networks (0) | 2022.03.29 |
| ANN 인공신경망을 이용해 자동차 연비 예측하기 EarlyStopping 콜백(callback) 사용 (0) | 2022.03.29 |
| Neural Networks (0) | 2022.03.29 |
| 딥러닝(tensorflow)을 이용한 자동차 구매 가격 예측 (0) | 2022.03.28 |