필요한 라이브러리 import
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten,Conv2D,MaxPooling2D
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt(X_train,y_train),(X_test,y_test) = mnist.load_data()이미지는 원래 컬러 이미지이므로, 1개의 이미지는 3차원 입니다.
따라서 이미지 처리를 CNN을 구성할때는, 전체 데이터셋은 4차원으로 구성해야합니다.
X_train=X_train.reshape(60000,28,28,1)
X_test=X_test.reshape(10000,28,28,1)
피처스케일링
X_train=X_train/255.0
X_test=X_test/255.0
CNN으로 모델링, 컴파일, 학습합니다.
model = Sequential()
model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu',input_shape = (28,28,1))) #첫번째는 input_shape 필수
model.add(MaxPooling2D(pool_size=(2,2),strides=2))
model.add(Conv2D(filters=64,kernel_size=(2,2),activation='relu'))
model.add(MaxPooling2D((2,2),2))
model.add(Flatten())
model.add(Dense(units=128,activation='relu'))
model.add(Dense(units=10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
model.fit(X_train,y_train,epochs=5)
학습이 끝나면 테스트셋으로 정확도를 확인합니다.
model.evaluate(X_test,y_test)
컨퓨전 매트릭스로 어떤 것을 틀렸는지 확인합니다.
from sklearn.metrics import confusion_matrix,accuracy_score
y_pred = model.predict(X_test)
y_pred=y_pred.argmax(axis=1)
cm = confusion_matrix(y_test,y_pred)
import seaborn as sb
sb.heatmap(data=cm,annot=True,fmt='.0f',cmap='RdPu')
트레이닝셋은 93% , 테스트셋은 91% 까지 나옵니다.
에포크를 20까지 해보면, 트레이닝셋 정확도는 올라가지만 밸리데이션 정확도는 내려갑니다.
즉, 오버핏팅이 됩니다.
import tensorflow as tf
mnist = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = mnist.load_data()
training_images=training_images.reshape(60000, 28, 28, 1)
training_images=training_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images=test_images/255.0위에서 만든 모델을 함수로 만들겠습니다.
그리고 학습할때 에포크를 20으로 해서 학습하겠습니다.
변수는 epoch_history로 사용해서 학습
def build_model():
model = Sequential()
model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu',input_shape = (28,28,1)))
model.add(MaxPooling2D(pool_size=(2,2),strides=2))
model.add(Conv2D(filters=64,kernel_size=(2,2),activation='relu'))
model.add(MaxPooling2D((2,2),2))
model.add(Flatten())
model.add(Dense(units=128,activation='relu'))
model.add(Dense(units=10,activation='softmax'))
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
return model모델 생성
model = build_model()모델 학습
epoch_history = model.fit(X_train,y_train,epochs=20,validation_split=0.2)
Accuracy 차트
plt.plot(epoch_history.history['accuracy'])
plt.plot(epoch_history.history['val_accuracy'])
plt.title('Model Accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(['Train','Validation'])
plt.show()
Loss 차트
plt.plot(epoch_history.history['loss'])
plt.plot(epoch_history.history['val_loss'])
plt.title('Model Loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend(['Train','Validation'])
plt.show()
Visualizing the Convolutions and Pooling
import matplotlib.pyplot as plt
f, axarr = plt.subplots(3,4)
FIRST_IMAGE=0
SECOND_IMAGE=7
THIRD_IMAGE=26
CONVOLUTION_NUMBER = 1
from tensorflow.keras import models
layer_outputs = [layer.output for layer in model.layers]
activation_model = tf.keras.models.Model(inputs = model.input, outputs = layer_outputs)
for x in range(0,4):
f1 = activation_model.predict(X_test[FIRST_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[0,x].imshow(f1[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[0,x].grid(False)
f2 = activation_model.predict(X_test[SECOND_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[1,x].imshow(f2[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[1,x].grid(False)
f3 = activation_model.predict(X_test[THIRD_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[2,x].imshow(f3[0, : , :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[2,x].grid(False)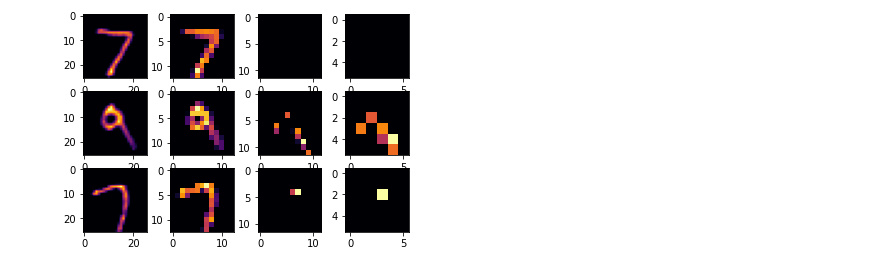
EXERCISES
1. 컨볼루션 필터 갯수를 16 또는 64로 바꿔서 정확도를 확인합니다.
2. 맨 마지막 컨볼루션 지우고 해봅니다
3. 콜백 셋팅해서 돌려봅니다.
모델생성
model = build_model()
얼리스탑핑 이용 방법
early_stop = tf.keras.callbacks.EarlyStopping(monitor='val_loss',patience=5)
콜백 클래스 이용 방법
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs={}):
if logs['val_accuracy'] > 0.99 :
print('\n벨리데이션 정확도가 99%가 넘으므로, 에포크를 멈춥니다.')
self.model.stop_training = Truemy_callback = myCallback()모델 학습
epoch_history = model.fit(X_train,y_train,epochs=20,validation_split=0.2,callbacks=[early_stop,my_callback])
'딥러닝' 카테고리의 다른 글
| CNN 이용하여 정교한 이미지 분류 (강아지, 고양이 분류) (0) | 2022.03.29 |
|---|---|
| Image Data Generator 사람과 말 분류 (0) | 2022.03.29 |
| ANN 인공신경망을 이용해 자동차 연비 예측하기 EarlyStopping 콜백(callback) 사용 (0) | 2022.03.29 |
| Neural Networks (0) | 2022.03.29 |
| 딥러닝(tensorflow)을 이용한 자동차 구매 가격 예측 (0) | 2022.03.28 |